Multiagent reinforcement learning algorithms (MARL) have been demonstrated on complex tasks that require the coordination of a team of multiple agents to complete. Existing works have focused on sharing information between agents via centralized critics to stabilize learning or through communication to increase performance, but do not generally look at how information can be shared between agents during training to address the curse of dimensionality in MARL. We propose that an n-agent multiagent problem can be decomposed into an n-task multitask problem where each agent explores a subset of the state space instead of exploring the entire state space.
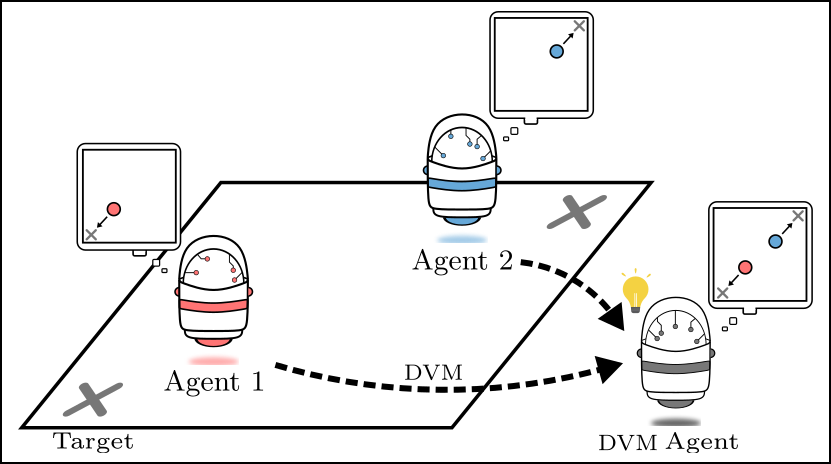
Figure 1: Agents can distill policies to combine knowledge
An example is illustrated in Figure 1 where agents must navigate to the closest target. This multiagent single-task problem can be decomposed into two symmetric single-agent tasks. In one case, an agent must learn a policy as though it were in Agent 1’s position; in the other, the agent must learn a policy for Agent 2’s position. The ability to share information enables agents to “divide and conquer”, where each agent only needs to learn how to complete the task from one perspective.