Reinforcement learning (RL) can be a tool for designing policies and controllers for robotic systems. However, the cost of real-world samples remains prohibitive as many RL algorithms require a large number of samples before learning useful policies. Simulators are one way to decrease the number of required real-world samples, but imperfect models make deciding when and how to trust samples from a simulator difficult.
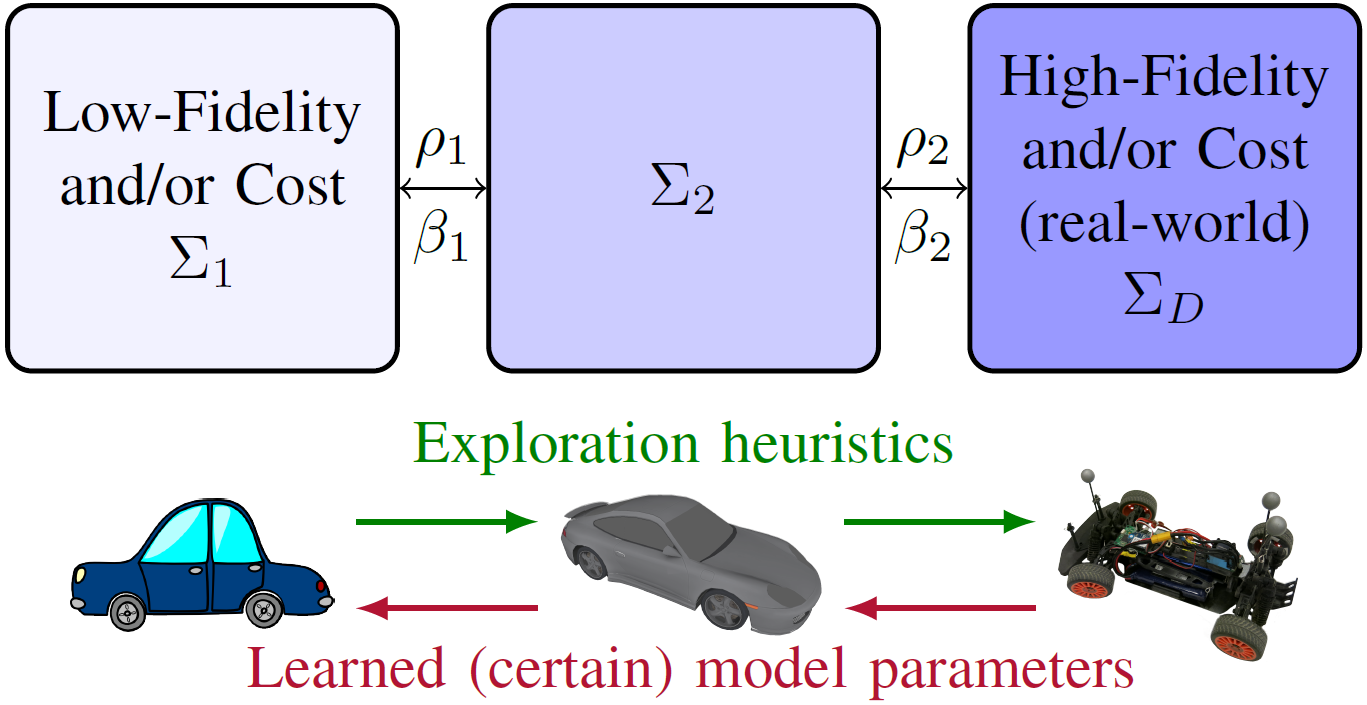
This project presents a framework for efficient RL in a scenario where multiple simulators of a target task are available, each with varying levels of fidelity. The framework is designed to limit the number of samples used in each successively higher-fidelity/cost simulator by allowing a learning agent to choose to run trajectories at the lowest level simulator that will still provide it with useful information. Theoretical proofs of the framework’s sample complexity are given and empirical results are demonstrated on a remote controlled car with multiple simulators. The approach enables RL algorithms to find near-optimal policies in a physical robot domain with fewer expensive real-world samples than previous transfer approaches or learning without simulators.