
Imitation Learning (IL) can generate computationally efficient policies from demonstrations provided by computationally expensive model-based algorithms, such as Model Predictive Control (MPC). However, commonly employed IL methods are often data-inefficient, requiring the collection of a large number of demonstrations and producing policies with limited robustness to uncertainties.
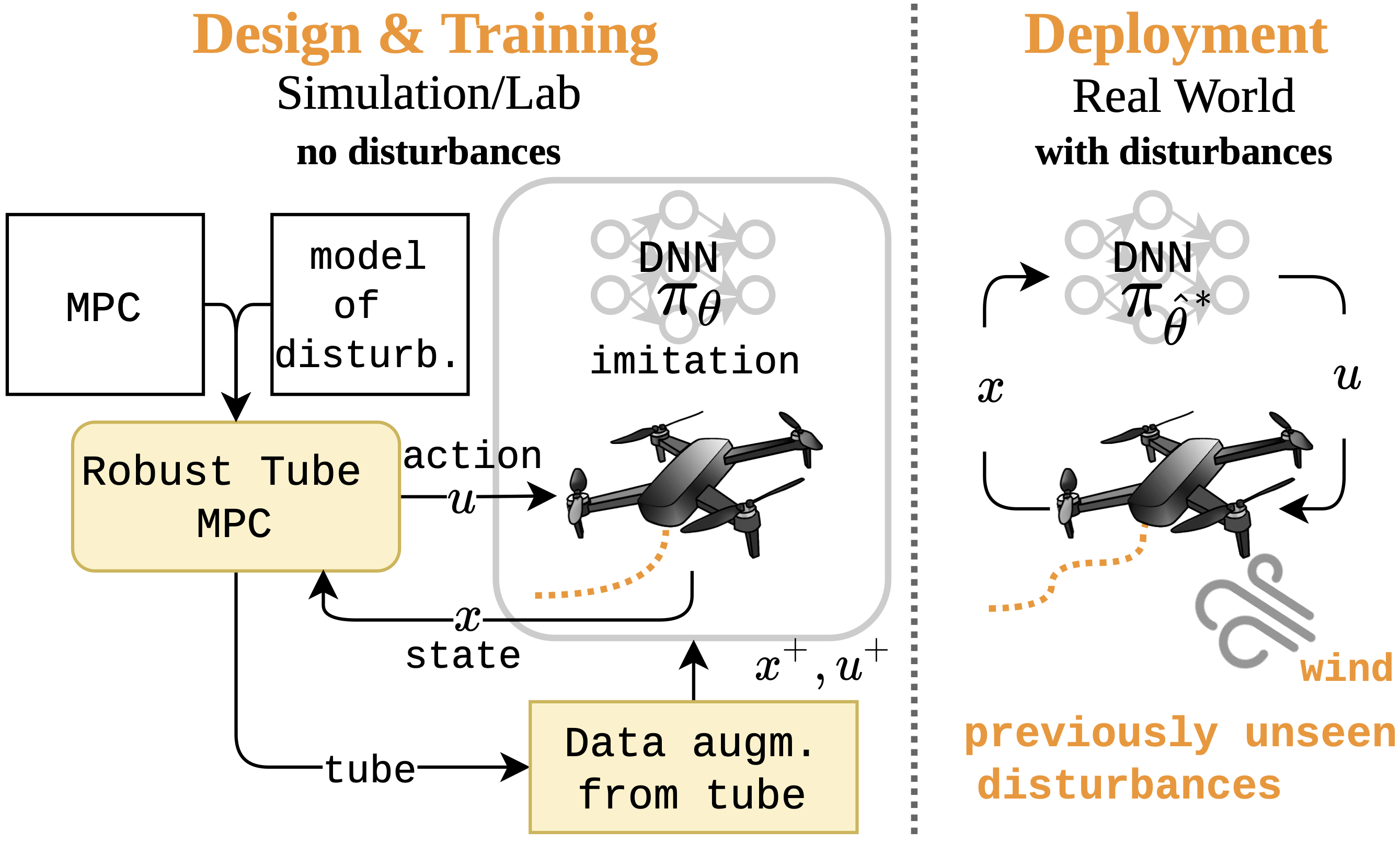
In the first part of this project, we address the robustness and demonstration efficiency challenges of IL by generating a Robust Tube variant of MPC (RTMPC) to collect demonstrations robust to process uncertainties (e.g., wind). We additionally leverage properties from the tube to introduce a data augmentation method that enables high demonstration-efficiency, capable of compensating the “distribution shifts” typically encountered in IL. Our approach opens to the possibility of zero-shot transfer from a single demonstration collected in a nominal domain, such as a simulation or a robot in a lab/controlled environment, to a domain with bounded model errors/perturbations. Experimental evaluations performed on a trajectory tracking MPC for a multirotor show that our method outperforms strategies commonly employed in IL, such as DAgger and Domain Randomization, in terms of demonstration-efficiency and robustness to perturbations unseen during training.
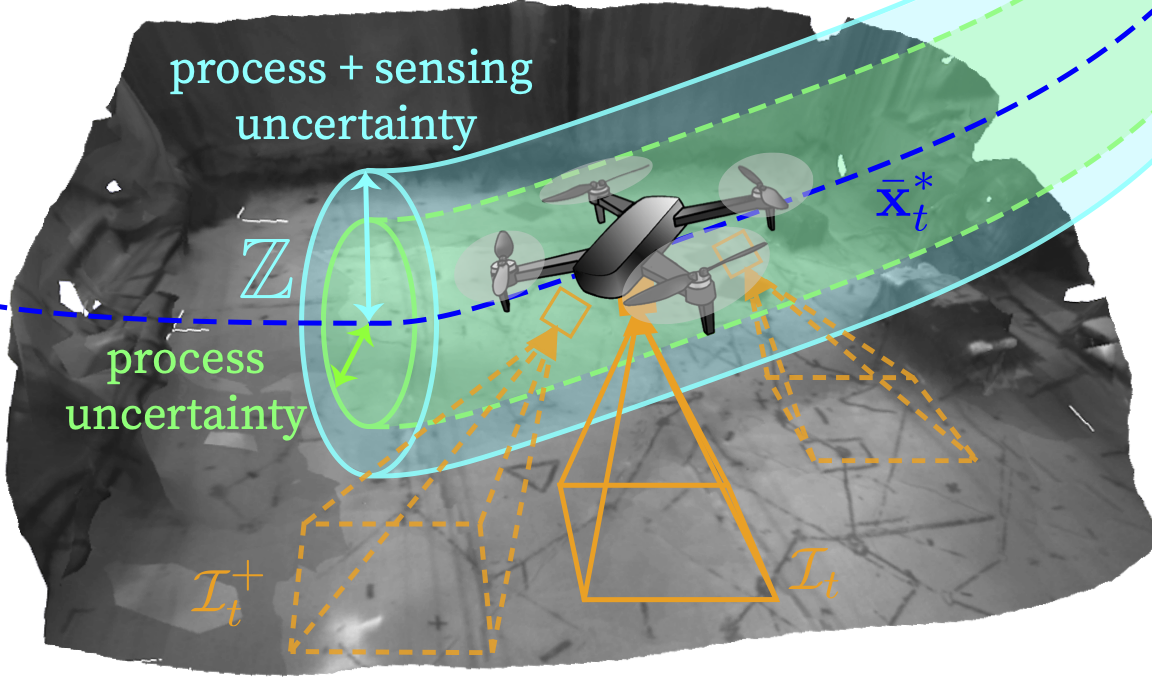
In the second part of this project, we additionally introduce the ability to efficiently learn robust sensorimotor policies, capable to control a mobile robot directly from noisy, high-dimensional sensory observations, such as images. Key to our approach is to combine IL with an output feedback RTMPC to generate demonstrations robust to the effects of process and sensing uncertainties (e.g., noise, drifts), and co-generate a data augmentation strategy to augment the demonstrations collected by IL methods. We tailor our approach to the task of learning a trajectory tracking visuomotor policy for an aerial robot, leveraging a 3D mesh of the environment as part of the data augmentation process. We numerically demonstrate that our method can learn to control a robot from images using a single demonstration—a two-orders of magnitude improvement in demonstration efficiency compared to existing IL methods.
This work is funded by the Air Force Office of Scientific Research MURI FA9550-19-1-0386